
很多人卡在做视频这一步,不是不会写内容,是没时间一遍遍录音。尤其是做保险、教育、法律咨询,或者个人IP的人,一条视频录十遍都不一定满意,热点一过,流量也没了。
从开麦录音,到生成可用克隆音色,最快几分钟就能完成。
我最近就遇到一个做知识付费的朋友。那天晚上九点,他给我发语音,说第二天要上线一套微课,PPT早就做好了,结果卡在配音。自己录,状态不稳。找别人录,味道不对。临时改稿,前面又得重来。
后来我让他直接去做声音克隆。
一、为什么声音克隆这件事,能直接解决内容产能问题
很多人以为声音克隆只是好玩,像给自己做个AI音色。其实不是。
真正有价值的地方,是你不用每次都重新开口录。
这件事对内容团队特别重要。因为视频生产最耗人的,往往不是写脚本,而是反复录音、重录、修错字、补情绪、卡节奏。传统短视频从脚本到成片,常常要几小时,甚至几天。可一旦把声音克隆先做好,后面很多内容就能直接复用。
我见过最典型的两个场景。
一个是保险经纪人。每天早上都要发朋友圈内容,产品解读、理赔案例、客户答疑。如果天天真人录,三天还新鲜,十天就累了。
另一个是培训机构。开课前要把几十页PPT变成微课视频。讲师档期一冲突,整个项目都往后拖。
这时候,AI声音克隆不是锦上添花,而是把最重的一块石头先搬走。
二、声音克隆页面,先看哪里
进入蝉镜AI的声音克隆页面后,页面上方就是克隆声音的入口。这一块很好理解,你要做自己的声音,就从上面进。
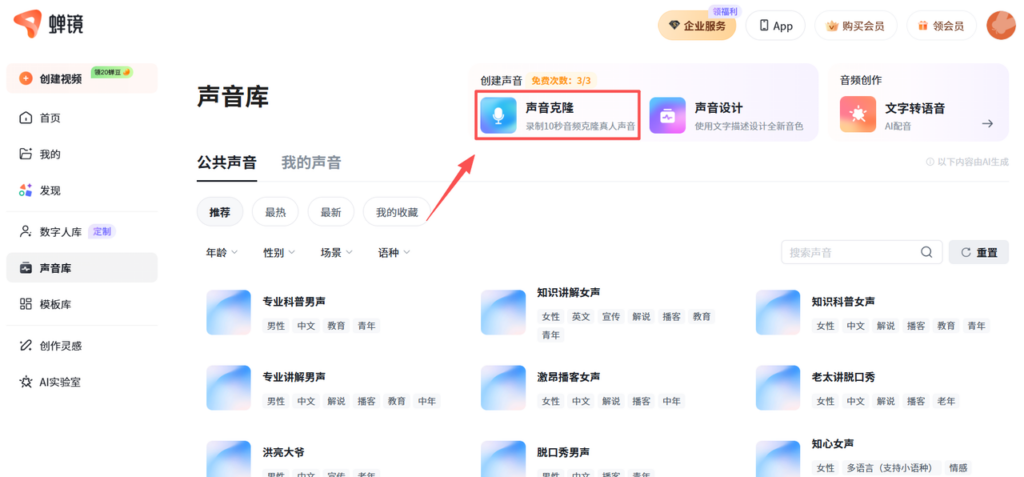
页面下方是平台提供的公共声音。如果你暂时还不想自己录,也可以先用筛选项去找合适的声音,或者直接输入声音名称搜索。很多人第一次用,都会先试听公共声音,找感觉,再决定要不要克隆自己的声音。
这个设计我觉得很实用。因为不是每个人一上来都敢直接做自己的音色,有个过渡区,压力会小很多。
三、我实际会怎么做,4步就够了
第一步,先开麦克风权限
点击前往设置,把麦克风权限打开。
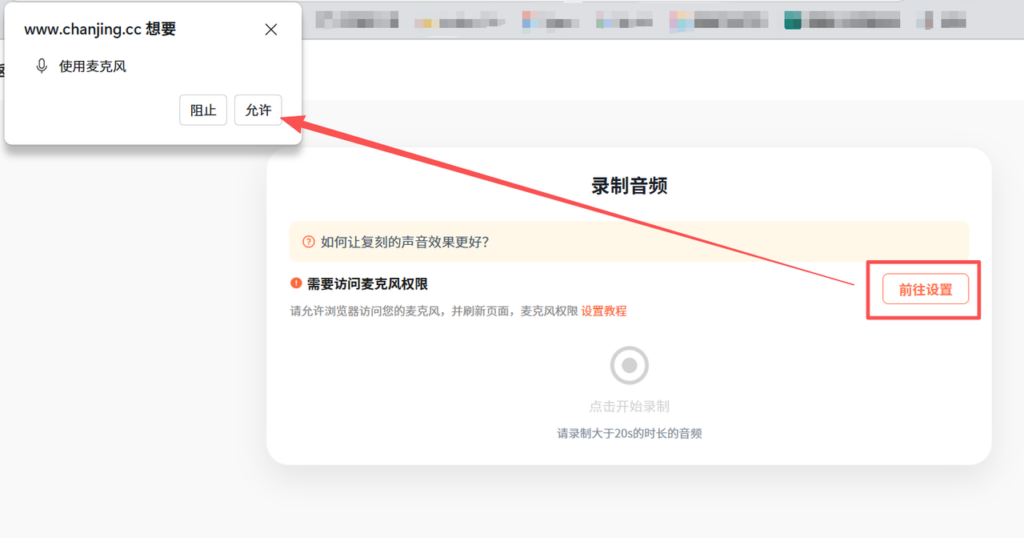
这一步别跳。很多人后面录不了,不是功能问题,是系统权限没开。尤其是第一次用电脑浏览器或者手机端的时候,系统会默认拦一下。如果你发现点了录音没反应,先别急着怀疑平台,先去看权限。
第二步,现场录制,或者上传音频
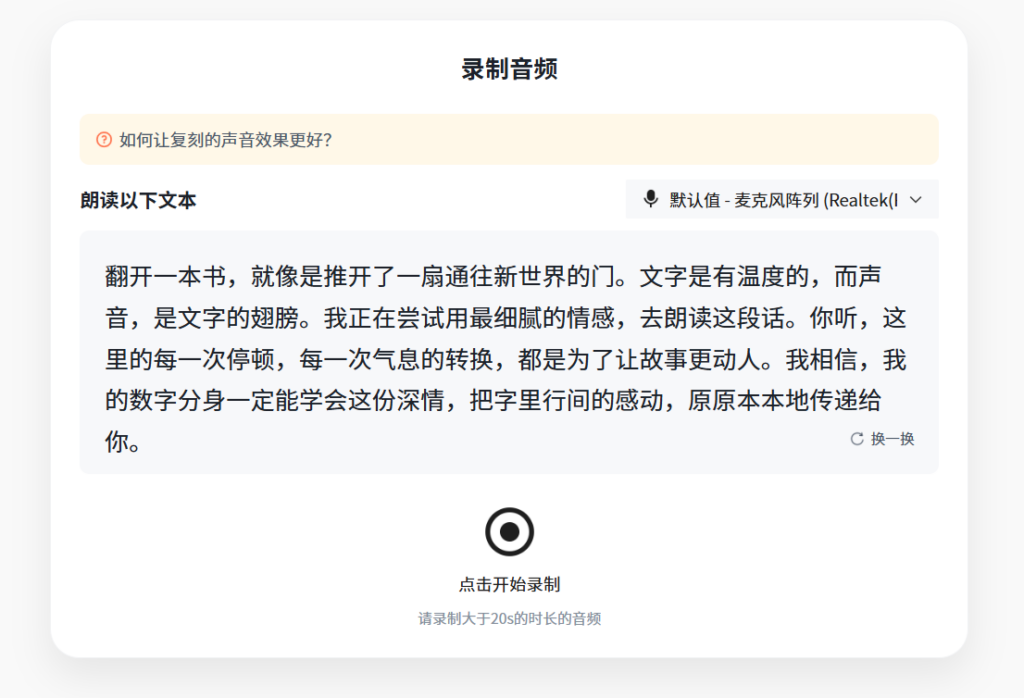
接下来就是录训练声音。你可以现场录,也可以上传已经准备好的音频文件。这里有两个关键点:
- 格式要符合平台支持范围。
- 声音质量一定要干净。
我自己的建议是:别在地铁站,别在有回声的会议室,别一边吹空调一边录。最稳的方法,是找个安静房间,手机静音,门关上,连续说一段自然的话。不要刻意夹嗓子,也不要故意播音腔,就用你平时最稳定的说话方式。
因为你后面要复用的是这个声音,不是一次性的表演。
第三步,等平台检测时长和质量
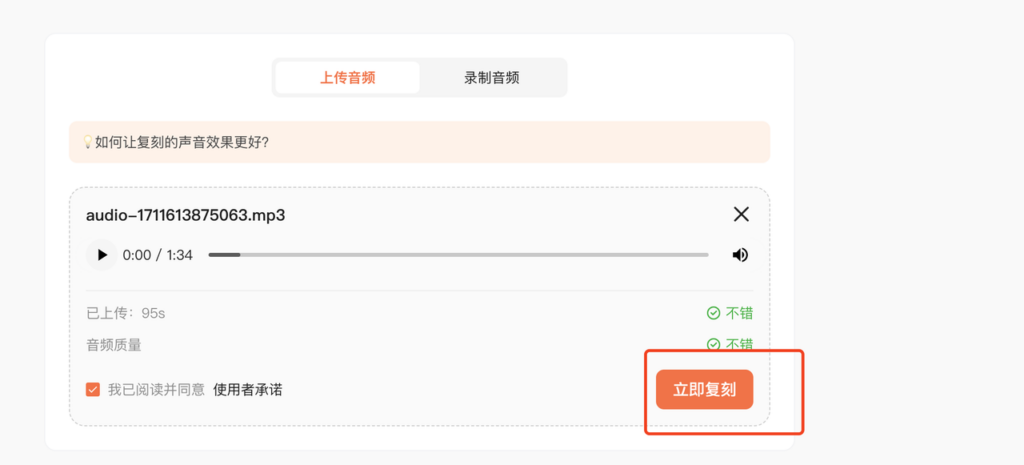
上传完成后,平台会自动检测声音时长和质量。
- 如果系统提示效果较差,我建议不要将就,直接重录。很多人最容易犯的错,就是想着“先试试再说”,结果克隆出来总觉得不像,又回头重新做,反而更浪费时间。
- 如果显示效果不错,就可以点击立即复刻。
这里通常不用等太久,稍等片刻就能完成。
第四步,试听两个版本,再保存
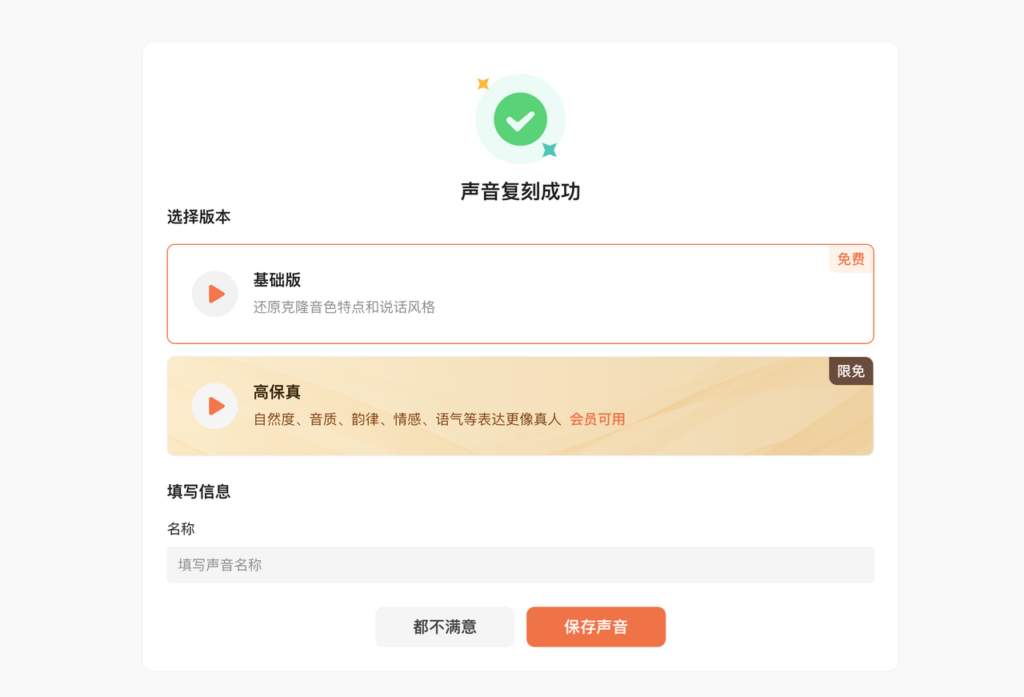
克隆完成后,平台会提供基础版和高保真版两个声音版本。
这一步一定要听。不要光看名字选。因为有些人会发现,基础版更利落,高保真版更像本人。到底哪个好,要看你拿去做什么。
- 如果你是做知识讲解,可能更在意清晰稳定。
- 如果你是做个人IP,可能更在意像不像自己。
试听后,选一个你满意的版本,输入名称,保存,就可以开始使用了。如果两个都不满意,也可以直接点“都不满意”,返回重新上传音频,再重新克隆一次。
这个细节我挺喜欢——不是强行让你在不满意里二选一,而是给你重来的机会。
四、什么样的人,最该先把声音克隆做好
保险和金融从业者
这类人特别适合。因为客户买的不是一条视频,是对你的信任。你每天发文字,客户未必记得你。你偶尔发真人视频,又很难长期坚持。可如果你有自己的克隆声音,再配合数字形象,内容就能持续输出,而且声音识别度会越来越强。尤其是私域场景,声音比文字更容易建立熟悉感。
教育和知识付费创作者
我认识一个讲职业考试的老师,去年冬天为了录一套课,连续说了两个星期,最后嗓子都哑了。最麻烦的是,后面课程一更新,还得补录。这种情况下,先把声音克隆做好,后面无论是PPT转讲解,还是知识点拆分,都轻松很多。
律师、会计、税务顾问这类专业服务者
这类人最缺的不是专业内容,而是稳定输出的时间。文章会写,不代表愿意天天录视频。可现在短视频和视频号又是获客入口,不做也不行。AI声音克隆的价值,就是把你最像你的那部分保留下来,让内容输出不再完全依赖你本人每天到场。
个人IP和矩阵操盘手
一个人运营多个平台,最怕的就是分身乏术。今天录抖音,明天录视频号,后天还要改小红书版本,光录音就能把人拖住。这时候,有自己的声音资产,内容节奏会一下子轻很多。
五、但我也得说句实话,不是所有音频都适合拿去克隆
这段话很重要,不说就像广告了。
声音克隆不是万能修音器。
如果你的原始音频本身就有很重的环境噪音、回声、喷麦、断句混乱,或者情绪特别飘,那克隆结果大概率也不会理想。平台可以复刻你的声音特征,但没法凭空把一段很差的素材变成录音棚级别。
还有一种情况,也不太适合一上来就追求高保真:就是你自己平时说话状态很不稳定。今天低沉,明天很尖,后天又特别快。那先别急着做,先找一个你最自然、也最适合长期输出的说话状态,再去录训练音频,效果会更好。
所以这件事的取舍很简单:想要后面省时间,就先在前面多花几分钟,把素材录好。
六、声音克隆做好之后,真正厉害的地方,不只是保存一个音色
我觉得很多人低估了这一点。
声音克隆不是一个孤零零的小功能,它真正值钱的地方,是能接到后面的内容生产链路里。
比如你本来做一条视频,要先想脚本,再录音,再配画面,再剪辑。现在如果前面的声音已经准备好了,后面就能更顺地接数字人和成片流程。尤其是做课程、做汇报、做营销内容的人,这种顺滑感非常明显。
蝉镜AI现在做得比较狠的一点,就是把这条链路压得很短。上传PPT或者PDF,AI自动生成讲解话术,再匹配数字人形象和声音一键合成,三步就能成片。平台日均生成需求超过10万,活跃用户超过50万,这说明它不是一个只能演示的功能,而是真的有人在高频使用。
再加上时长单价低至0.04元每秒,注册还送60蝉豆,能直接生成1分钟视频。对于第一次想试的人,这个门槛已经很低了。
七、如果你现在就想上手,我建议你这样试一次
别一上来就想着做一整套内容矩阵。
你先拿一个最真实的场景试。
- 比如你是保险经纪人,就做一条明天要发朋友圈的保险知识视频。
- 你是培训老师,就拿一页PPT做一段30秒讲解。
- 你是律师,就把最近客户最常问的一个问题,做成一条简短口播。
先把声音克隆做出来,试听,保存。然后立刻拿它去生成一条真正会发出去的内容。你只要完成这一次,就会很直观地知道,这到底是不是你要的效率工具。
我见过很多人,原本只是想试试声音克隆,结果最后真正留下来的,不是那个音色本身,而是终于摆脱了反复录音这件事。
如果你也正卡在出镜难、录音慢、内容产能跟不上这一步,可以直接去试试蝉镜AI的声音克隆。先做出你的声音,再把它变成你持续出现在客户面前的内容资产。